The vision-language navigation research group in robotics and artificial intelligence lab (RAIL), Tongji University.
No. 4800, Cao'an Highway,
Jiading District,
Shanghai, China
The Robotics and Artificial Intelligence Laboratory (RAIL) at Tongji University, established in 1990, is one of the earliest labs in China dedicated to research in robotics and artificial intelligence. The laboratory focuses on scientific research in areas such as industrial robots, autonomous mobile robots, 2D/3D vision, and humanoid robots.
The RAIL-VLN research group was established in 2021, focusing on end-to-end mapless navigation for mobile robots. The group has developed a service robot as an experimental platform, and is actively expanding its research towards general and practical embodied intelligence.
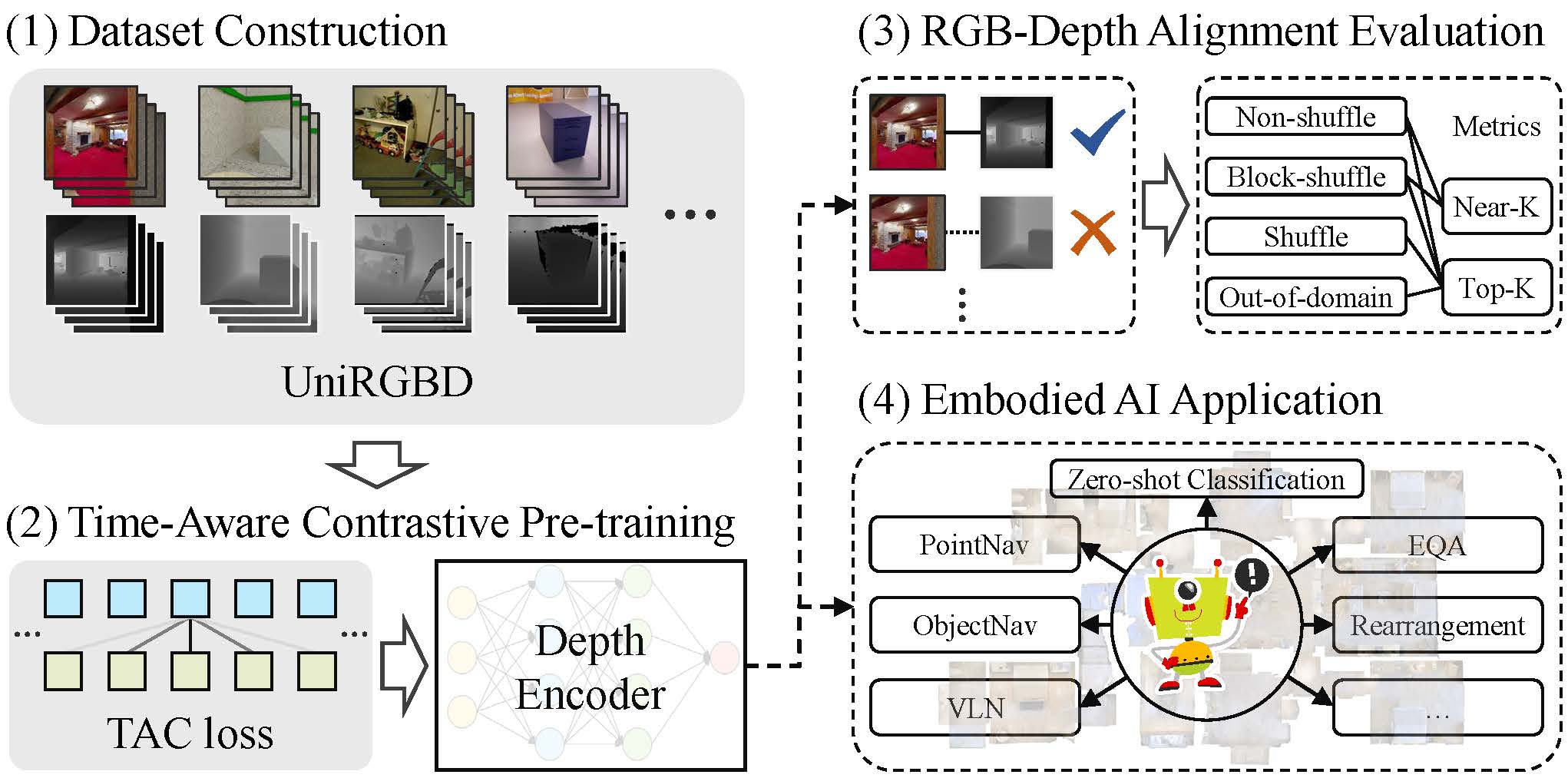
Existing end-to-end depth representation in embodied AI is often task-specific and lacks the benefits of emerging pre-training paradigm due to limited datasets and training techniques for RGB-D videos. To address the challenge of obtaining robust and generalized depth representation for embodied AI, we introduce a unified RGB-D video dataset (UniRGBD) and a novel time-aware contrastive (TAC) pre-training approach. UniRGBD addresses the scarcity of large-scale depth pre-training datasets by providing a comprehensive collection of data from diverse sources in a unified format, enabling convenient data loading and accommodating various data domains. We also design an RGB-Depth alignment evaluation procedure and introduce a novel Near-K accuracy metric to assess the scene understanding capability of the depth encoder. Then, the TAC pre-training approach fills the gap in depth pre-training methods suitable for RGB-D videos by leveraging the intrinsic similarity between temporally proximate frames. TAC incorporates a soft label design that acts as valid label noise, enhancing the depth semantic extraction and promoting diverse and generalized knowledge acquisition. Furthermore, the adjustments in perspective between temporally proximate frames facilitate the extraction of invariant and comprehensive features, enhancing the robustness of the learned depth representation. Additionally, the inclusion of temporal information stabilizes training gradients and enables spatio-temporal depth perception. Comprehensive evaluation of RGB-Depth alignment demonstrates the superiority of our approach over state-of-the-art methods. We also conduct uncertainty analysis and a novel zero-shot experiment to validate the robustness and generalization of the TAC approach. Moreover, our TAC pre-training demonstrates significant performance improvements in various embodied AI tasks, providing compelling evidence of its efficacy across diverse domains.
@article{10288539,author={He, Zongtao and Wang, Liuyi and Dang, Ronghao and Li, Shu and Yan, Qingqing and Liu, Chengju and Chen, Qijun},journal={IEEE Transactions on Circuits and Systems for Video Technology},title={Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-Training},year={2024},volume={34},number={6},pages={4143-4158},keywords={Task analysis;Artificial intelligence;Videos;Training;Databases;Visualization;Feature extraction;Depth representation;pre-training methods;contrastive learning;embodied AI},doi={10.1109/TCSVT.2023.3326373},issn={1558-2205},month=jun,}
IEEE:
Z. He, L. Wang, R. Dang, S. Li, Q. Yan, C. Liu, and Q. Chen, “Learning depth representation from RGB-d videos by time-aware contrastive pre-training,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 6, pp. 4143–4158, Jun. 2024, doi: 10.1109/TCSVT.2023.3326373
APA:
He, Z., Wang, L., Dang, R., Li, S., Yan, Q., Liu, C., & Chen, Q. (2024). Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-Training. IEEE Transactions on Circuits and Systems for Video Technology, 34(6), 4143–4158. https://doi.org/10.1109/TCSVT.2023.3326373
GOAT
Vision-and-Language Navigation via Causal Learning
Liuyi Wang, Zongtao He, Ronghao Dang, and 3 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
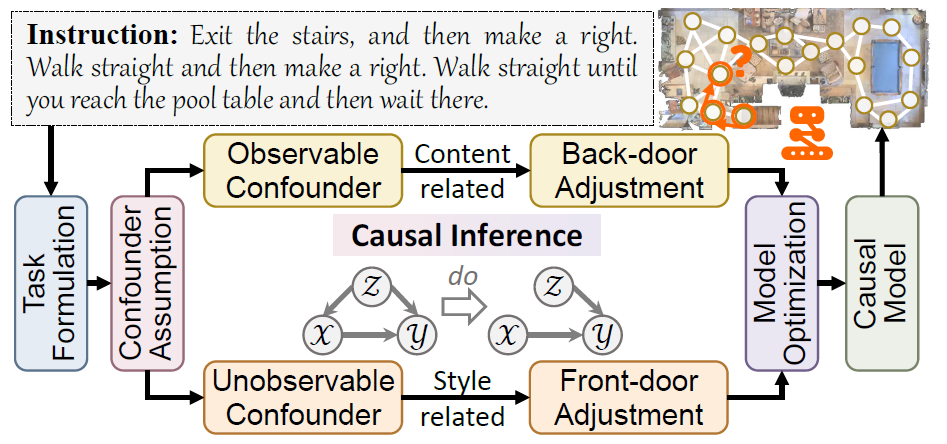
In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-andlanguage navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
@inproceedings{Wang_2024_GOAT,author={Wang, Liuyi and He, Zongtao and Dang, Ronghao and Shen, Mengjiao and Liu, Chengju and Chen, Qijun},title={Vision-and-Language Navigation via Causal Learning},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},month=jun,year={2024},pages={13139-13150},doi={10.1109/CVPR52733.2024.01248},}
IEEE:
L. Wang, Z. He, R. Dang, M. Shen, C. Liu, and Q. Chen, “Vision-and-language navigation via causal learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Jun. 2024, pp. 13139–13150. doi: 10.1109/CVPR52733.2024.01248
APA:
Wang, L., He, Z., Dang, R., Shen, M., Liu, C., & Chen, Q. (2024). Vision-and-Language Navigation via Causal Learning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 13139–13150. https://doi.org/10.1109/CVPR52733.2024.01248
MAT
Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation
Ronghao Dang, Lu Chen, Liuyi Wang, and 3 more authors
In Proceedings of the 40th International Conference on Machine Learning (ICML), Jul 2023
We propose a meta-ability decoupling (MAD) paradigm, which brings together various object navigation methods in an architecture system, allowing them to mutually enhance each other and evolve together. Based on the MAD paradigm, we design a multiple thinking (MT) model that leverages distinct thinking to abstract various meta-abilities. Our method decouples meta-abilities from three aspects: input, encoding, and reward while employing the multiple thinking collaboration (MTC) module to promote mutual cooperation between thinking. MAD introduces a novel qualitative and quantitative interpretability system for object navigation. Through extensive experiments on AI2-Thor and RoboTHOR, we demonstrate that our method outperforms state-of-the-art (SOTA) methods on both typical and zero-shot object navigation tasks.
@inproceedings{dang2023multiple,title={Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation},author={Dang, Ronghao and Chen, Lu and Wang, Liuyi and He, Zongtao and Liu, Chengju and Chen, Qijun},booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML)},pages={6855--6872},volume={202},year={2023},month=jul,}
IEEE:
R. Dang, L. Chen, L. Wang, Z. He, C. Liu, and Q. Chen, “Multiple thinking achieving meta-ability decoupling for object navigation,” in Proceedings of the 40th international conference on machine learning (ICML), Jul. 2023
APA:
Dang, R., Chen, L., Wang, L., He, Z., Liu, C., & Chen, Q. (2023). Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation. Proceedings of the 40th International Conference on Machine Learning (ICML), 202, 6855–6872.