MEE Project
Multimodal Evolutionary Encoder for Continuous Vision-Language Navigation
More Works from Our Lab
Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-Training
IEEE Transactions on Circuits and Systems for Video Technology 2024NavComposer: Composing Language Instructions for Navigation Trajectories through Action-Scene-Object Modularization
IEEE Transactions on Circuits and Systems for Video Technology (Early Access)Vision-and-Language Navigation via Causal Learning
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Multimodal Evolutionary Encoder for Continuous Vision-Language Navigation
Abstract
Can multimodal encoder evolve when facing increasingly tough circumstances? Our work investigates this possibility in the context of continuous vision-language navigation (continuous VLN), which aims to navigate robots under linguistic supervision and visual feedback. We propose a multimodal evolutionary encoder (MEE) comprising a unified multimodal encoder architecture and an evolutionary pre-training strategy. The unified multimodal encoder unifies rich modalities, including depth and sub-instruction, to enhance the solid understanding of environments and tasks. It also effectively utilizes monocular observation, reducing the reliance on panoramic vision. The evolutionary pre-training strategy exposes the encoder to increasingly unfamiliar data domains and difficult objectives. The multi-stage adaption helps the encoder establish robust inner- and inter-modality connections and improve its generalization to unfamiliar environments. To achieve such evolution, we collect a large-scale multi-stage dataset with specialized objectives, addressing the absence of suitable continuous VLN pre-training. Evaluation on VLN-CE demonstrates the superiority of MEE over other direct action-predicting methods. Furthermore, we deploy MEE in real scenes using self-developed service robots, showcasing its effectiveness and potential for real-world applications.
Method
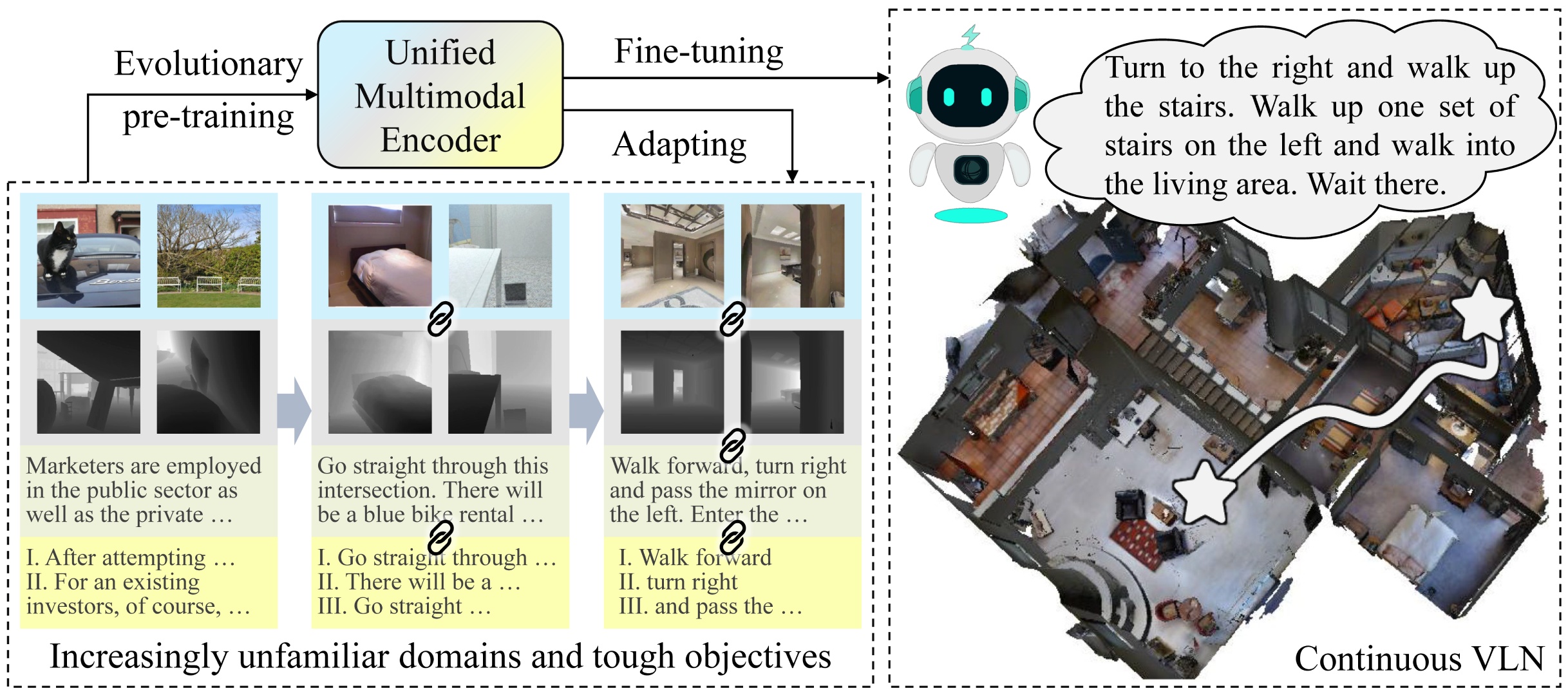
Overall procedure.
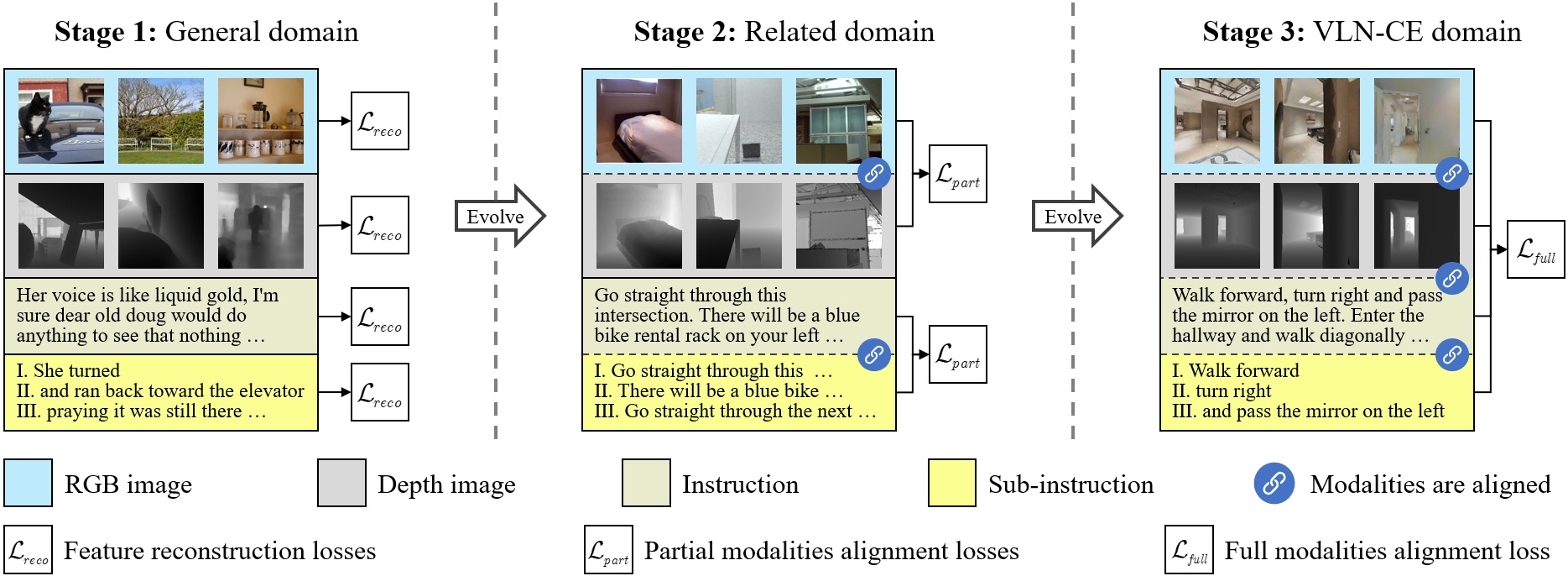
The evolutionary pre-training procedure and dataset.
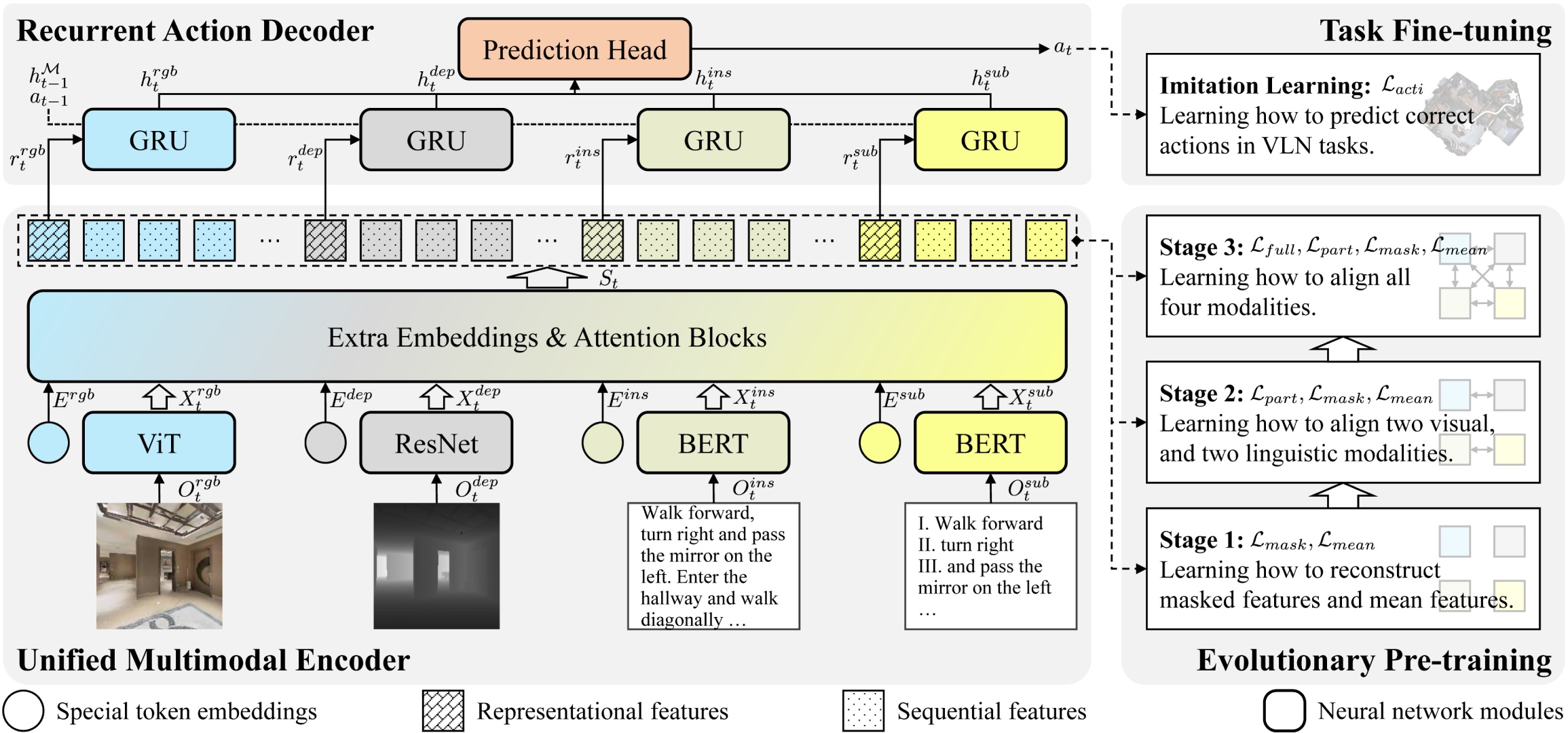
The model architecture.
Main Contributions
- The unified multimodal encoder enhances comprehensive perception with unified features while reduces the reliance on panoramas.
- The evolutionary pre-training enables the encoder to evolve better feature representations and generalization ability across multiple stages.
- Both simulated and real scene experiments validate the effectiveness of MEE. Code and datasets have been publicly released.
BibTeX
@INPROCEEDINGS{10802484,
author={He, Zongtao and Wang, Liuyi and Chen, Lu and Li, Shu and Yan, Qingqing and Liu, Chengju and Chen, Qijun},
booktitle={2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
title={Multimodal Evolutionary Encoder for Continuous Vision-Language Navigation},
year={2024},
volume={},
number={},
pages={1443-1450},
keywords={Visualization;Costs;Codes;Navigation;Service robots;Linguistics;Feature extraction;Solids;Decoding;Intelligent robots},
doi={10.1109/IROS58592.2024.10802484}
}