publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- TSOG
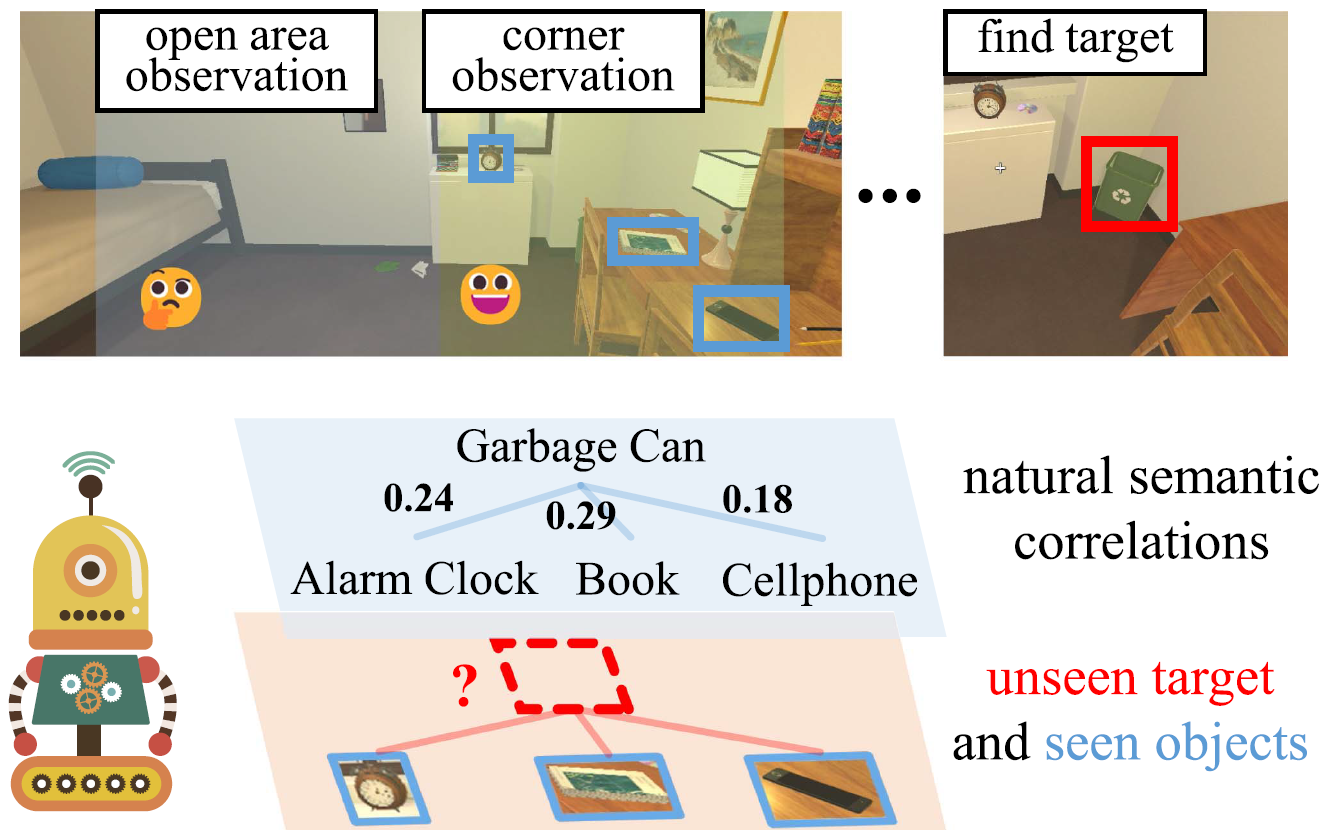 Temporal Scene-Object Graph Learning for Object NavigationLu Chen, Zongtao He, Liuyi Wang, and 2 more authorsIEEE Robotics and Automation Letters, May 2025
Temporal Scene-Object Graph Learning for Object NavigationLu Chen, Zongtao He, Liuyi Wang, and 2 more authorsIEEE Robotics and Automation Letters, May 2025Object navigation tasks require agents to locate target objects within unfamiliar indoor environments. However, the first-person perspective inherently imposes limited visibility, complicating global planning. Hence, it becomes imperative for the agent to cultivate an efficient visual representation from this restricted viewpoint. To address this, we introduce a temporal scene-object graph (TSOG) to construct an informative and efficient ego-centric visual representation. Firstly, we develop a holistic object feature descriptor (HOFD) to fully describe object features from different aspects, facilitating the learning of relationships between observed and unseen objects. Next, we propose a scene-object graph (SOG) to simultaneously learn local and global correlations between objects and agent observations, granting the agent a more comprehensive and flexible scene understanding ability. This facilitates the agent to perform target association and search more efficiently. Finally, we introduce a temporal graph aggregation (TGA) module to dynamically aggregate memory information across consecutive time steps. TGA offers the agent a dynamic perspective on historical steps, aiding in navigation towards the target in longer trajectories. Extensive experiments in AI2THOR and Gibson datasets demonstrate our method’s effectiveness and efficiency for ObjectNav tasks in unseen environments.
@article{10933547, author = {Chen, Lu and He, Zongtao and Wang, Liuyi and Liu, Chengju and Chen, Qijun}, journal = {IEEE Robotics and Automation Letters}, title = {Temporal Scene-Object Graph Learning for Object Navigation}, year = {2025}, month = may, volume = {10}, number = {5}, pages = {4914-4921}, keywords = {Navigation;Correlation;Visualization;Semantics;Feature extraction;Training;Artificial intelligence;Aggregates;Trajectory;Reinforcement learning;Vision-based navigation;reinforcement learning;representation learning;autonomous agents}, doi = {10.1109/LRA.2025.3553055}, }IEEE:
L. Chen, Z. He, L. Wang, C. Liu and Q. Chen, "Temporal Scene-Object Graph Learning for Object Navigation," IEEE Robotics and Automation Letters, vol. 10, no. 5, pp. 4914-4921, May 2025, doi: 10.1109/LRA.2025.3553055
APA:
Chen, L., He, Z., Wang, L., Liu, C., & Chen, Q. (2025). Temporal Scene-Object Graph Learning for Object Navigation. IEEE Robotics and Automation Letters, 10(5), 4914–4921. https://doi.org/10.1109/LRA.2025.3553055
- MLANet
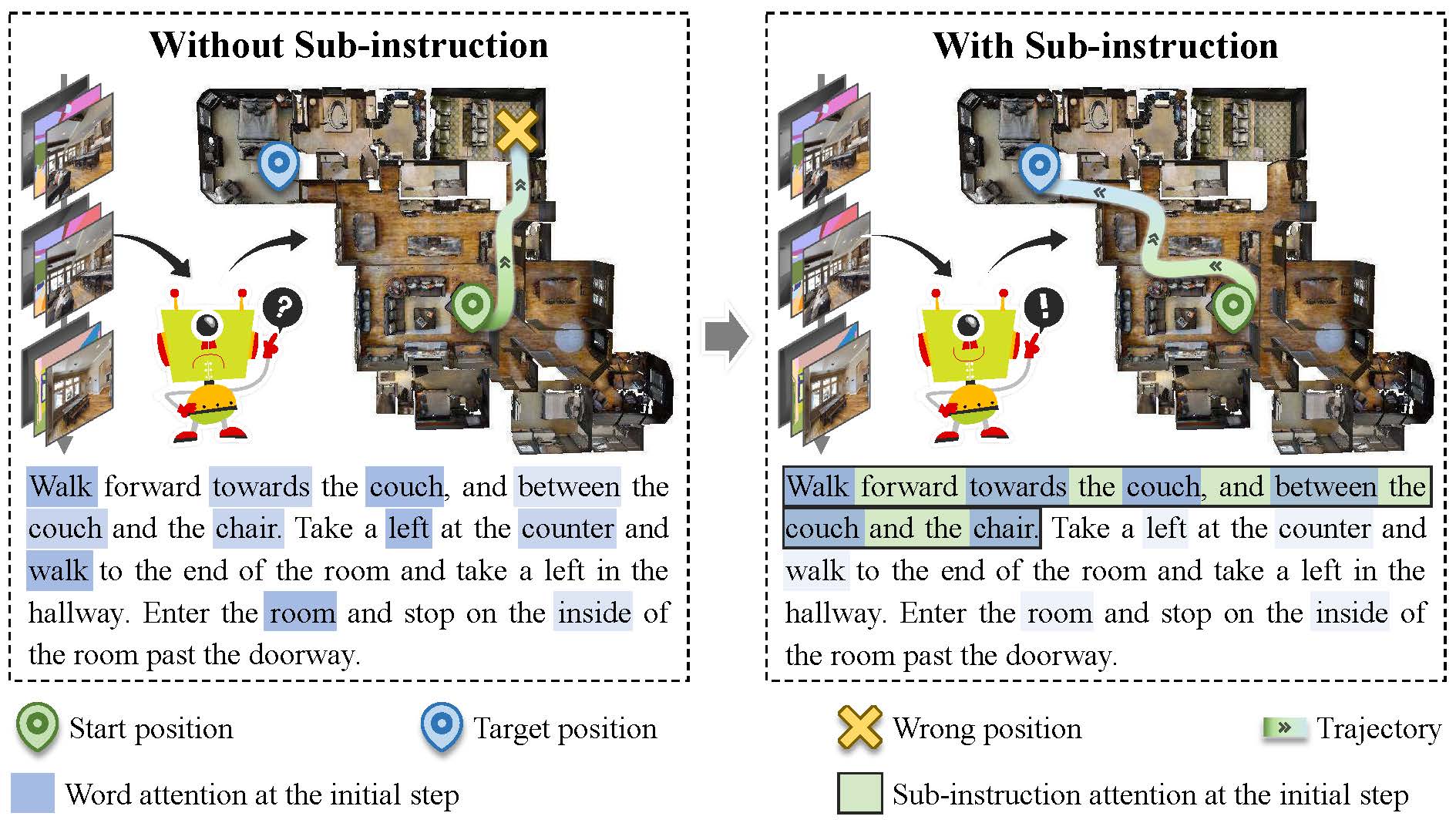 A Multilevel Attention Network with Sub-Instructions for Continuous Vision-and-Language NavigationZongtao He, Liuyi Wang, Shu Li, and 3 more authorsApplied Intelligence, Apr 2025
A Multilevel Attention Network with Sub-Instructions for Continuous Vision-and-Language NavigationZongtao He, Liuyi Wang, Shu Li, and 3 more authorsApplied Intelligence, Apr 2025The aim of vision-and-language navigation (VLN) is to develop agents that navigate mapless environments via linguistic and visual observations. Continuous VLN, which more accurately mirrors real-world conditions than its discrete counterpart does, faces unique challenges such as real-time execution, complex instruction understanding, and long sequence prediction. In this work, we introduce a multilevel instruction understanding mechanism and propose a multilevel attention network (MLANet) to address these challenges. Initially, we develop a nonlearning-based fast sub-instruction algorithm (FSA) to swiftly generate sub-instructions without the need for annotations, achieving a speed enhancement of 28 times over the previous methods. Subsequently, our multilevel attention (MLA) module dynamically integrates visual features with both high- and low-level linguistic semantics, forming multilevel global semantics to bolster the complex instruction understanding capabilities of the model. Finally, we introduce the peak attention loss (PAL), which enables the flexible and adaptive selection of the current sub-instruction, thereby improving accuracy and stability achieved for long trajectories by focusing on the relevant local semantics. Our experimental findings demonstrate that MLANet significantly outperforms the baselines and is applicable to real-world robots.
@article{He2025_MLANet, title = {A Multilevel Attention Network with Sub-Instructions for Continuous Vision-and-Language Navigation}, author = {He, Zongtao and Wang, Liuyi and Li, Shu and Yan, Qingqing and Liu, Chengju and Chen, Qijun}, year = {2025}, month = apr, journal = {Applied Intelligence}, volume = {55}, number = {7}, pages = {657}, issn = {1573-7497}, doi = {10.1007/s10489-025-06544-9}, }IEEE:
Z. He, L. Wang, S. Li, Q. Yan, C. Liu, and Q. Chen, “A multilevel attention network with sub-instructions for continuous vision-and-language navigation,” Applied Intelligence, vol. 55, no. 7, p. 657, Apr. 2025, doi: 10.1007/s10489-025-06544-9
APA:
He, Z., Wang, L., Li, S., Yan, Q., Liu, C., & Chen, Q. (2025). A Multilevel Attention Network with Sub-Instructions for Continuous Vision-and-Language Navigation. Applied Intelligence, 55(7), 657. https://doi.org/10.1007/s10489-025-06544-9
- NavComposer: Composing Language Instructions for Navigation Trajectories through Action-Scene-Object ModularizationZongtao He, Liuyi Wang, Lu Chen, and 2 more authorsIEEE Transactions on Circuits and Systems for Video Technology, 2025
- Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual DisparitiesLiuyi Wang, Xinyuan Xia, Hui Zhao, and 6 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2025
2024
- TAC
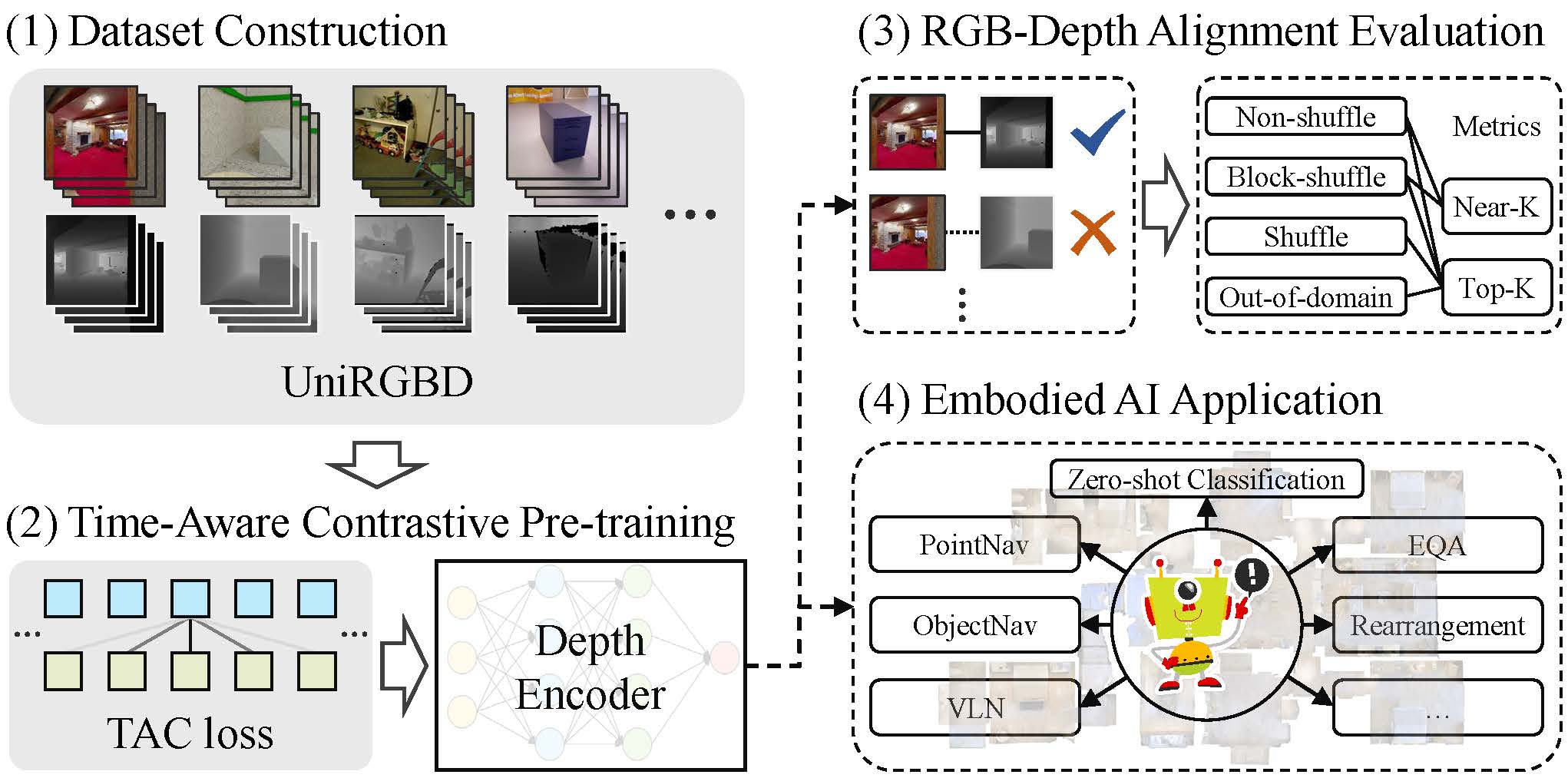 Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-TrainingZongtao He, Liuyi Wang, Ronghao Dang, and 4 more authorsIEEE Transactions on Circuits and Systems for Video Technology, Jun 2024
Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-TrainingZongtao He, Liuyi Wang, Ronghao Dang, and 4 more authorsIEEE Transactions on Circuits and Systems for Video Technology, Jun 2024Existing end-to-end depth representation in embodied AI is often task-specific and lacks the benefits of emerging pre-training paradigm due to limited datasets and training techniques for RGB-D videos. To address the challenge of obtaining robust and generalized depth representation for embodied AI, we introduce a unified RGB-D video dataset (UniRGBD) and a novel time-aware contrastive (TAC) pre-training approach. UniRGBD addresses the scarcity of large-scale depth pre-training datasets by providing a comprehensive collection of data from diverse sources in a unified format, enabling convenient data loading and accommodating various data domains. We also design an RGB-Depth alignment evaluation procedure and introduce a novel Near-K accuracy metric to assess the scene understanding capability of the depth encoder. Then, the TAC pre-training approach fills the gap in depth pre-training methods suitable for RGB-D videos by leveraging the intrinsic similarity between temporally proximate frames. TAC incorporates a soft label design that acts as valid label noise, enhancing the depth semantic extraction and promoting diverse and generalized knowledge acquisition. Furthermore, the adjustments in perspective between temporally proximate frames facilitate the extraction of invariant and comprehensive features, enhancing the robustness of the learned depth representation. Additionally, the inclusion of temporal information stabilizes training gradients and enables spatio-temporal depth perception. Comprehensive evaluation of RGB-Depth alignment demonstrates the superiority of our approach over state-of-the-art methods. We also conduct uncertainty analysis and a novel zero-shot experiment to validate the robustness and generalization of the TAC approach. Moreover, our TAC pre-training demonstrates significant performance improvements in various embodied AI tasks, providing compelling evidence of its efficacy across diverse domains.
@article{10288539, author = {He, Zongtao and Wang, Liuyi and Dang, Ronghao and Li, Shu and Yan, Qingqing and Liu, Chengju and Chen, Qijun}, journal = {IEEE Transactions on Circuits and Systems for Video Technology}, title = {Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-Training}, year = {2024}, volume = {34}, number = {6}, pages = {4143-4158}, keywords = {Task analysis;Artificial intelligence;Videos;Training;Databases;Visualization;Feature extraction;Depth representation;pre-training methods;contrastive learning;embodied AI}, doi = {10.1109/TCSVT.2023.3326373}, issn = {1558-2205}, month = jun, }IEEE:
Z. He, L. Wang, R. Dang, S. Li, Q. Yan, C. Liu, and Q. Chen, “Learning depth representation from RGB-d videos by time-aware contrastive pre-training,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 6, pp. 4143–4158, Jun. 2024, doi: 10.1109/TCSVT.2023.3326373
APA:
He, Z., Wang, L., Dang, R., Li, S., Yan, Q., Liu, C., & Chen, Q. (2024). Learning Depth Representation From RGB-D Videos by Time-Aware Contrastive Pre-Training. IEEE Transactions on Circuits and Systems for Video Technology, 34(6), 4143–4158. https://doi.org/10.1109/TCSVT.2023.3326373
- IA-HWP
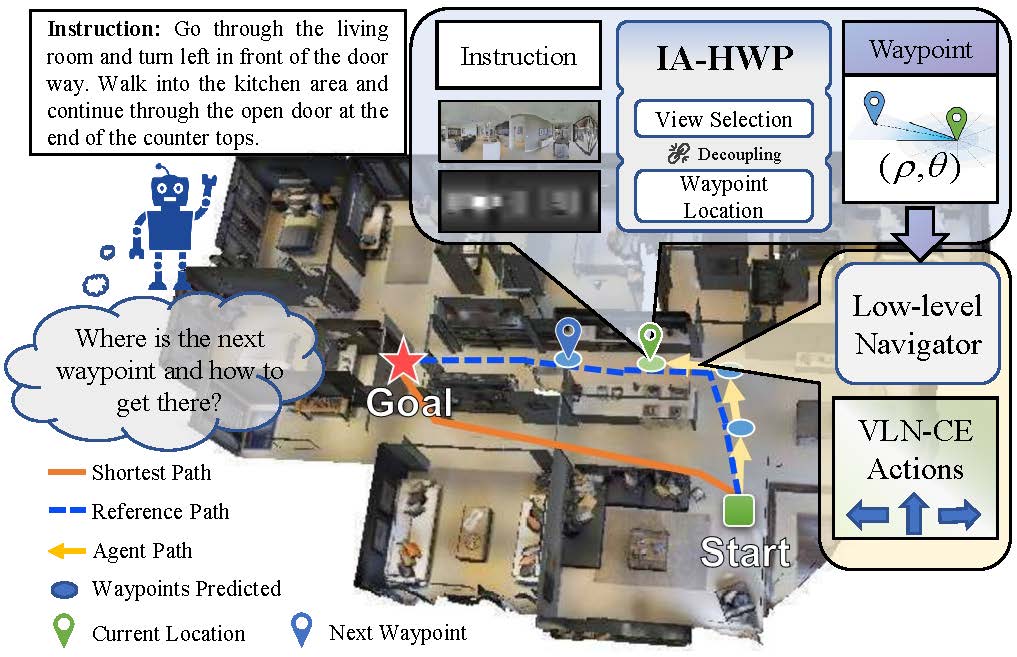 Instruction-aligned hierarchical waypoint planner for vision-and-language navigation in continuous environmentsZongtao He, Naijia Wang, Liuyi Wang, and 2 more authorsPattern Analysis and Applications, Oct 2024
Instruction-aligned hierarchical waypoint planner for vision-and-language navigation in continuous environmentsZongtao He, Naijia Wang, Liuyi Wang, and 2 more authorsPattern Analysis and Applications, Oct 2024Developing agents to follow language instructions is a compelling yet challenging research topic. Recently, vision-and-language navigation in continuous environments has been proposed to explore the multi-modal pattern analysis and mapless navigation abilities of intelligent agents. However, current waypoint-based methods still have shortcomings, such as the coupled decision process and the possible shortest path-instruction misalignment. To address these challenges, we propose an instruction-aligned hierarchical waypoint planner (IA-HWP) that ensures fine-grained waypoint prediction and enhances instruction alignment. Our HWP architecture decouples waypoint planning into a coarse view selection phase and a refined waypoint location phase, effectively improving waypoint quality and enabling specialized training supervision for different phases. In terms of instruction-aligned model design, we introduce the global action-vision co-grounding and local text-vision co-grounding modules to explicitly improve the understanding of visual landmarks and actions, thereby enhancing the alignment between instructions and trajectories. In terms of instruction-aligned model optimization, we employ reference-waypoint-oriented supervision and direction-aware loss to optimize the model for enhanced instruction following and waypoint execution capabilities. Experiments on the standard benchmark demonstrate the effectiveness of our approach, with improved success rate compared to existing methods.
@article{He2024_IAHWP, author = {He, Zongtao and Wang, Naijia and Wang, Liuyi and Liu, Chengju and Chen, Qijun}, title = {Instruction-aligned hierarchical waypoint planner for vision-and-language navigation in continuous environments}, journal = {Pattern Analysis and Applications}, year = {2024}, month = oct, day = {03}, volume = {27}, number = {4}, pages = {132}, issn = {1433-755X}, doi = {10.1007/s10044-024-01339-z}, url = {https://doi.org/10.1007/s10044-024-01339-z}, }IEEE:
Z. He, N. Wang, L. Wang, C. Liu, and Q. Chen, “Instruction-aligned hierarchical waypoint planner for vision-and-language navigation in continuous environments,” Pattern Analysis and Applications, vol. 27, no. 4, p. 132, Oct. 2024, doi: 10.1007/s10044-024-01339-z
APA:
He, Z., Wang, N., Wang, L., Liu, C., & Chen, Q. (2024). Instruction-aligned hierarchical waypoint planner for vision-and-language navigation in continuous environments. Pattern Analysis and Applications, 27(4), 132. https://doi.org/10.1007/s10044-024-01339-z
- MEE
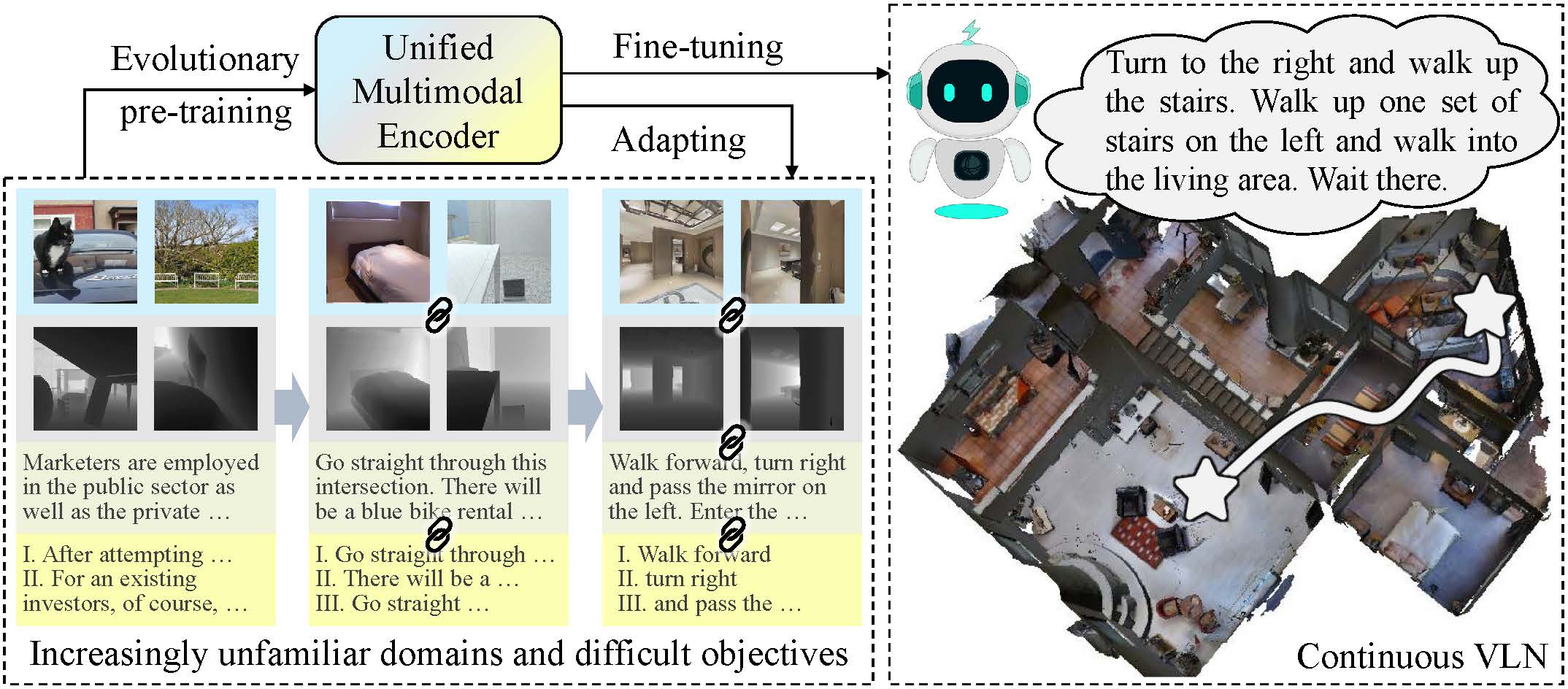 Multimodal Evolutionary Encoder for Continuous Vision-Language NavigationZongtao He, Liuyi Wang, Lu Chen, and 4 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024
Multimodal Evolutionary Encoder for Continuous Vision-Language NavigationZongtao He, Liuyi Wang, Lu Chen, and 4 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct 2024Can multimodal encoder evolve when facing increasingly tough circumstances? Our work investigates this possibility in the context of continuous vision-language navigation (continuous VLN), which aims to navigate robots under linguistic supervision and visual feedback. We propose a multimodal evolutionary encoder (MEE) comprising a unified multimodal encoder architecture and an evolutionary pre-training strategy. The unified multimodal encoder unifies rich modalities, including depth and sub-instruction, to enhance the solid understanding of environments and tasks. It also effectively utilizes monocular observation, reducing the reliance on panoramic vision. The evolutionary pre-training strategy exposes the encoder to increasingly unfamiliar data domains and difficult objectives. The multi-stage adaption helps the encoder establish robust intra- and inter-modality connections and improve its generalization to unfamiliar environments. To achieve such evolution, we collect a large-scale multi-stage dataset with specialized objectives, addressing the absence of suitable continuous VLN pre-training. Evaluation on VLN-CE demonstrates the superiority of MEE over other direct action-predicting methods. Furthermore, we deploy MEE in real scenes using self-developed service robots, showcasing its effectiveness and potential for real-world applications. Our code and dataset are available at https://github.com/RavenKiller/MEE.
@inproceedings{10802484, author = {He, Zongtao and Wang, Liuyi and Chen, Lu and Li, Shu and Yan, Qingqing and Liu, Chengju and Chen, Qijun}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, title = {Multimodal Evolutionary Encoder for Continuous Vision-Language Navigation}, year = {2024}, volume = {}, number = {}, pages = {1443-1450}, keywords = {Visualization;Costs;Codes;Navigation;Service robots;Linguistics;Feature extraction;Solids;Decoding;Intelligent robots}, doi = {10.1109/IROS58592.2024.10802484}, issn = {2153-0866}, month = oct, }IEEE:
Z. He, L. Wang, L. Chen, S. Li, Q. Yan, C. Liu, and Q. Chen, “Multimodal evolutionary encoder for continuous vision-language navigation,” in 2024 IEEE/RSJ international conference on intelligent robots and systems (IROS), Oct. 2024, pp. 1443–1450. doi: 10.1109/IROS58592.2024.10802484
APA:
He, Z., Wang, L., Chen, L., Li, S., Yan, Q., Liu, C., & Chen, Q. (2024). Multimodal Evolutionary Encoder for Continuous Vision-Language Navigation. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 1443–1450. https://doi.org/10.1109/IROS58592.2024.10802484
- GOAT
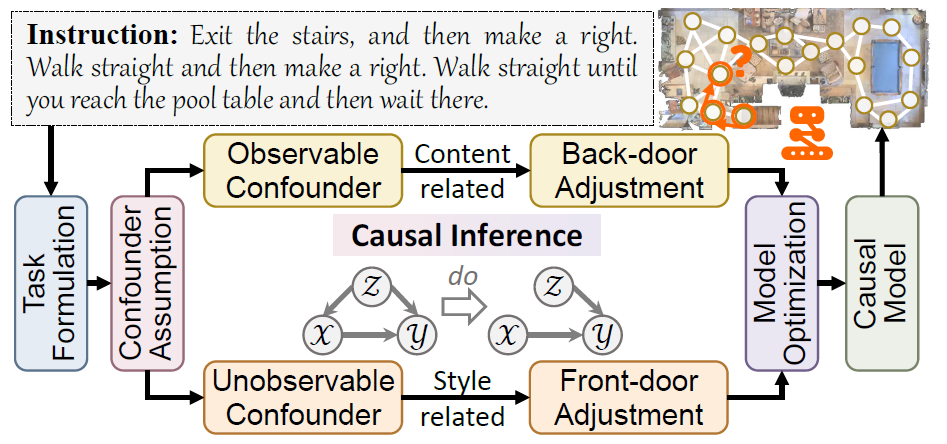 Vision-and-Language Navigation via Causal LearningLiuyi Wang, Zongtao He, Ronghao Dang, and 3 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024
Vision-and-Language Navigation via Causal LearningLiuyi Wang, Zongtao He, Ronghao Dang, and 3 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-andlanguage navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
@inproceedings{Wang_2024_GOAT, author = {Wang, Liuyi and He, Zongtao and Dang, Ronghao and Shen, Mengjiao and Liu, Chengju and Chen, Qijun}, title = {Vision-and-Language Navigation via Causal Learning}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2024}, pages = {13139-13150}, doi = {10.1109/CVPR52733.2024.01248}, }IEEE:
L. Wang, Z. He, R. Dang, M. Shen, C. Liu, and Q. Chen, “Vision-and-language navigation via causal learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Jun. 2024, pp. 13139–13150. doi: 10.1109/CVPR52733.2024.01248
APA:
Wang, L., He, Z., Dang, R., Shen, M., Liu, C., & Chen, Q. (2024). Vision-and-Language Navigation via Causal Learning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 13139–13150. https://doi.org/10.1109/CVPR52733.2024.01248
- SEAT
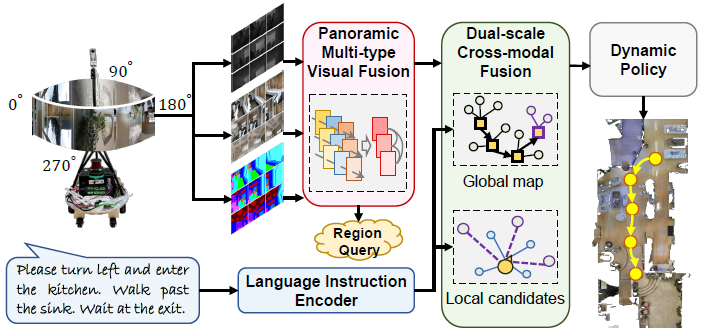 Enhanced Language-guided Robot Navigation with Panoramic Semantic Depth Perception and Cross-modal FusionLiuyi Wang, Jiagui Tang, Zongtao He, and 3 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
Enhanced Language-guided Robot Navigation with Panoramic Semantic Depth Perception and Cross-modal FusionLiuyi Wang, Jiagui Tang, Zongtao He, and 3 more authorsIn 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024Integrating visual observation with linguistic instruction holds significant promise for enhancing robot navigation across unstructured environments and enriches the human-robot interaction experience. However, while panoramic RGB views furnish robots with extensive environmental visuals, current methods significantly overlook crucial semantic and depth cues. This incomplete representation may lead to misinterpretation or inadequate execution of language instructions, thereby impeding navigation performance and adaptability. In this paper, we introduce SEAT, a semantic-depth aware cross-modal transformer model. Our approach incorporates an efficient panoramic multi-type visual encoder to capture comprehensive environmental details. To mitigate the rigidity of feature mapping stemming from the freezing of pre-training encoders, we propose a novel region query pre-training task. Additionally, we leverage an improved dual-scale cross-modal transformer to facilitate the integration of instructions, topological memory, and action prediction. Extensive experiments on three language-guided robot navigation datasets demonstrate the efficacy of our model, achieving competitive navigation success rates with fewer parameters and computational load. Furthermore, we validate SEAT’s effectiveness in real-world scenarios by deploying it on a mobile robot across various environments. The code is available at https://github.com/CrystalSixone/SEAT.
@inproceedings{wang2024enhanced, title = {Enhanced Language-guided Robot Navigation with Panoramic Semantic Depth Perception and Cross-modal Fusion}, author = {Wang, Liuyi and Tang, Jiagui and He, Zongtao and Dang, Ronghao and Liu, Chengju and Chen, Qijun}, booktitle = {2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, pages = {7726--7733}, year = {2024}, doi = {10.1109/IROS58592.2024.10801563}, organization = {IEEE}, }IEEE:
L. Wang, J. Tang, Z. He, R. Dang, C. Liu, and Q. Chen, “Enhanced language-guided robot navigation with panoramic semantic depth perception and cross-modal fusion,” in 2024 IEEE/RSJ international conference on intelligent robots and systems (IROS), IEEE, 2024, pp. 7726–7733. doi: 10.1109/IROS58592.2024.10801563
APA:
Wang, L., Tang, J., He, Z., Dang, R., Liu, C., & Chen, Q. (2024). Enhanced Language-guided Robot Navigation with Panoramic Semantic Depth Perception and Cross-modal Fusion. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 7726–7733. https://doi.org/10.1109/IROS58592.2024.10801563
2023
- PASTS
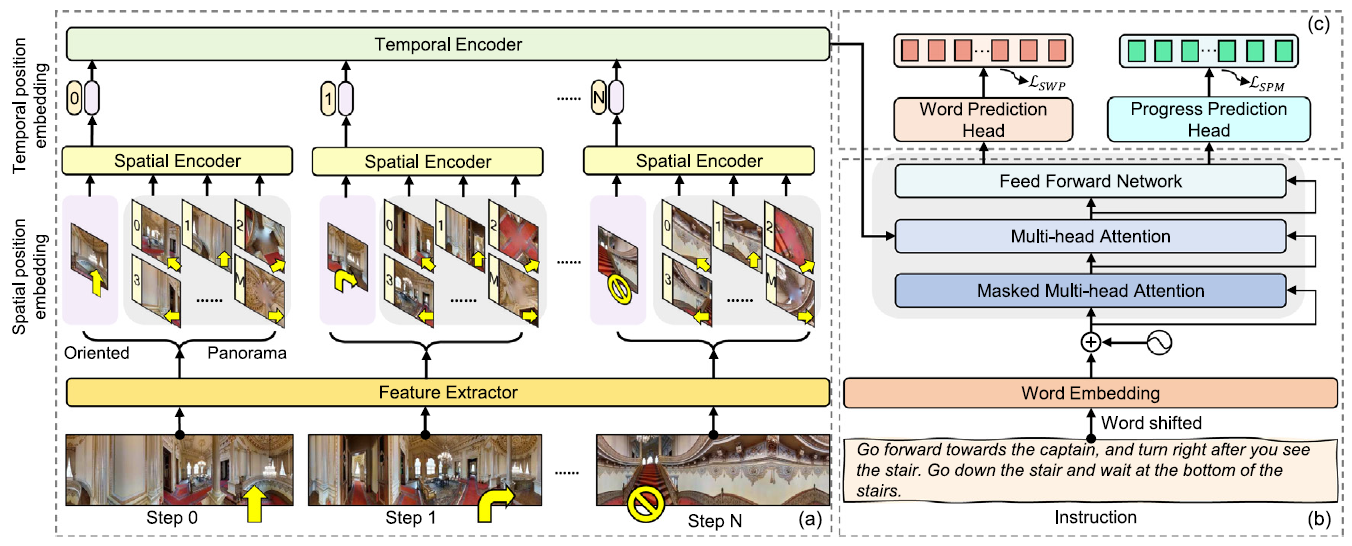 PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language NavigationLiuyi Wang, Chengju Liu, Zongtao He, and 4 more authorsEngineering Applications of Artificial Intelligence, 2023
PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language NavigationLiuyi Wang, Chengju Liu, Zongtao He, and 4 more authorsEngineering Applications of Artificial Intelligence, 2023Vision-and-language navigation (VLN) is a crucial but challenging cross-modal navigation task. One powerful technique to enhance the generalization performance in VLN is the use of an independent speaker model to provide pseudo instructions for data augmentation. However, current speaker models based on Long-Short Term Memory (LSTM) lack the ability to attend to features relevant at different locations and time steps. To address this, we propose a novel progress-aware spatio-temporal transformer speaker (PASTS) model that uses the transformer as the core of the network. PASTS uses a spatio-temporal encoder to fuse panoramic representations and encode intermediate connections through steps. Besides, to avoid the misalignment problem that could result in incorrect supervision, a speaker progress monitor (SPM) is proposed to enable the model to estimate the progress of instruction generation and facilitate more fine-grained caption results. Additionally, a multifeature dropout (MFD) strategy is introduced to alleviate overfitting. The proposed PASTS is flexible to be combined with existing VLN models. The experimental results demonstrate that PASTS outperforms previous speaker models and successfully improves the performance of previous VLN models, achieving state-of-the-art performance on the standard Room-to-Room (R2R) dataset.
@article{wang2023pasts, title = {PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language Navigation}, author = {Wang, Liuyi and Liu, Chengju and He, Zongtao and Li, Shu and Yan, Qingqing and Chen, Huiyi and Chen, Qijun}, journal = {Engineering Applications of Artificial Intelligence}, year = {2023}, doi = {https://doi.org/10.1016/j.engappai.2023.107487}, }IEEE:
L. Wang, C. Liu, Z. He, S. Li, Q. Yan, H. Chen, and Q. Chen, “PASTS: Progress-aware spatio-temporal transformer speaker for vision-and-language navigation,” Engineering Applications of Artificial Intelligence, 2023, doi: https://doi.org/10.1016/j.engappai.2023.107487
APA:
Wang, L., Liu, C., He, Z., Li, S., Yan, Q., Chen, H., & Chen, Q. (2023). PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language Navigation. Engineering Applications of Artificial Intelligence. https://doi.org/https://doi.org/10.1016/j.engappai.2023.107487
- DSRG
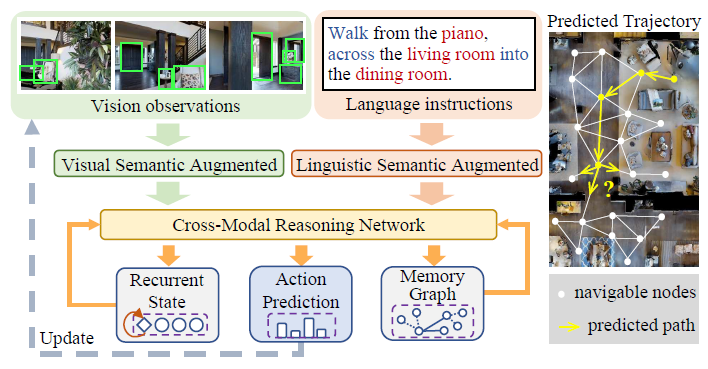 A Dual Semantic-Aware Recurrent Global-Adaptive Network for Vision-and-Language NavigationLiuyi Wang, Zongtao He, Jiagui Tang, and 4 more authorsIn Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, Aug 2023Main Track
A Dual Semantic-Aware Recurrent Global-Adaptive Network for Vision-and-Language NavigationLiuyi Wang, Zongtao He, Jiagui Tang, and 4 more authorsIn Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, Aug 2023Main TrackVision-and-Language Navigation (VLN) is a realistic but challenging task that requires an agent to locate the target region using verbal and visual cues. While significant advancements have been achieved recently, there are still two broad limitations: (1) The explicit information mining for significant guiding semantics concealed in both vision and language is still under-explored; (2) The previously structured map method provides the average historical appearance of visited nodes, while it ignores distinctive contributions of various images and potent information retention in the reasoning process. This work proposes a dual semantic-aware recurrent global-adaptive network (DSRG) to address the above problems. First, DSRG proposes an instruction-guidance linguistic module (IGL) and an appearance-semantics visual module (ASV) for boosting vision and language semantic learning respectively. For the memory mechanism, a global adaptive aggregation module (GAA) is devised for explicit panoramic observation fusion, and a recurrent memory fusion module (RMF) is introduced to supply implicit temporal hidden states. Extensive experimental results on the R2R and REVERIE datasets demonstrate that our method achieves better performance than existing methods. Code is available at https://github.com/CrystalSixone/DSRG.
@inproceedings{ijcai2023p164, title = {A Dual Semantic-Aware Recurrent Global-Adaptive Network for Vision-and-Language Navigation}, author = {Wang, Liuyi and He, Zongtao and Tang, Jiagui and Dang, Ronghao and Wang, Naijia and Liu, Chengju and Chen, Qijun}, booktitle = {Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, {IJCAI-23}}, publisher = {International Joint Conferences on Artificial Intelligence Organization}, editor = {Elkind, Edith}, pages = {1479--1487}, year = {2023}, month = aug, note = {Main Track}, doi = {10.24963/ijcai.2023/164}, url = {https://doi.org/10.24963/ijcai.2023/164}, }IEEE:
L. Wang, Z. He, J. Tang, R. Dang, N. Wang, C. Liu, and Q. Chen, “A dual semantic-aware recurrent global-adaptive network for vision-and-language navigation,” in Proceedings of the thirty-second international joint conference on artificial intelligence, IJCAI-23, E. Elkind, Ed., International Joint Conferences on Artificial Intelligence Organization, Aug. 2023, pp. 1479–1487. doi: 10.24963/ijcai.2023/164
APA:
Wang, L., He, Z., Tang, J., Dang, R., Wang, N., Liu, C., & Chen, Q. (2023). A Dual Semantic-Aware Recurrent Global-Adaptive Network for Vision-and-Language Navigation. In E. Elkind (Ed.), Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23 (pp. 1479–1487). International Joint Conferences on Artificial Intelligence Organization. https://doi.org/10.24963/ijcai.2023/164
- RES-StS
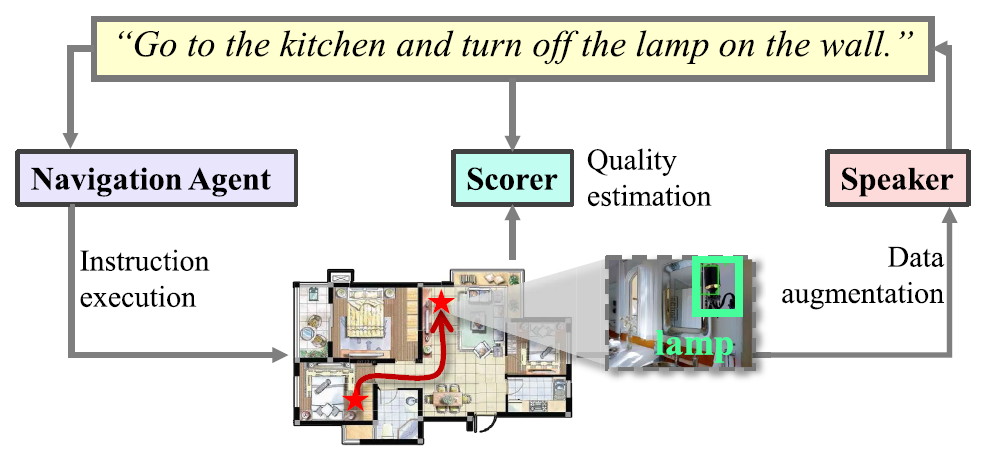 RES-StS: Referring Expression Speaker via Self-training with Scorer for Goal-Oriented Vision-Language NavigationLiuyi Wang, Zongtao He, Ronghao Dang, and 3 more authorsIEEE Transactions on Circuits and Systems for Video Technology, 2023
RES-StS: Referring Expression Speaker via Self-training with Scorer for Goal-Oriented Vision-Language NavigationLiuyi Wang, Zongtao He, Ronghao Dang, and 3 more authorsIEEE Transactions on Circuits and Systems for Video Technology, 2023It is a rather practical but difficult task to find a specified target object via autonomous exploration based on natural language descriptions in an unstructured environment. Since the human-annotated data is expensive to gather for the goal-oriented vision-language navigation (GVLN) task, the size of the standard dataset is inadequate, which has significantly limited the accuracy of previous techniques. In this work, we aim to improve the robustness and generalization of the navigator by dynamically providing high-quality pseudo-instructions using a proposed RES-StS paradigm. Specifically, we establish a referring expression speaker (RES) to predict descriptive instructions for the given path to the goal object. Based on an environment-andobject fusion (EOF) module, RES derives spatial representations from the input trajectories, which are subsequently encoded by a number of transformer layers. Additionally, given that the quality of the pseudo labels is important for data augmentation while the limited dataset may also hinder RES learning, we propose to equip RES with a more effective generation ability by using the self-training approach. A trajectory-instruction matching scorer (TIMS) network based on contrastive learning is proposed to selectively use rehearsal of prior knowledge. Finally, all network modules in the system are integrated by suggesting a multi-stage training strategy, allowing them to assist one another and thus enhance performance on the GVLN task. Experimental results demonstrate the effectiveness of our approach. Compared with the SOTA methods, our method improves SR, SPL, and RGS by 4.72%, 2.55%, and 3.45% respectively, on the REVERIE dataset, and 4.58%, 3.75% and 3.14% respectively, on the SOON dataset.
@article{wang2023res, title = {RES-StS: Referring Expression Speaker via Self-training with Scorer for Goal-Oriented Vision-Language Navigation}, author = {Wang, Liuyi and He, Zongtao and Dang, Ronghao and Chen, Huiyi and Liu, Chengju and Chen, Qijun}, journal = {IEEE Transactions on Circuits and Systems for Video Technology}, year = {2023}, doi = {10.1109/TCSVT.2022.3233554}, publisher = {IEEE}, }IEEE:
L. Wang, Z. He, R. Dang, H. Chen, C. Liu, and Q. Chen, “RES-StS: Referring expression speaker via self-training with scorer for goal-oriented vision-language navigation,” IEEE Transactions on Circuits and Systems for Video Technology, 2023, doi: 10.1109/TCSVT.2022.3233554
APA:
Wang, L., He, Z., Dang, R., Chen, H., Liu, C., & Chen, Q. (2023). RES-StS: Referring Expression Speaker via Self-training with Scorer for Goal-Oriented Vision-Language Navigation. IEEE Transactions on Circuits and Systems for Video Technology. https://doi.org/10.1109/TCSVT.2022.3233554
- MAT
 Multiple Thinking Achieving Meta-Ability Decoupling for Object NavigationRonghao Dang, Lu Chen, Liuyi Wang, and 3 more authorsIn Proceedings of the 40th International Conference on Machine Learning (ICML), Jul 2023
Multiple Thinking Achieving Meta-Ability Decoupling for Object NavigationRonghao Dang, Lu Chen, Liuyi Wang, and 3 more authorsIn Proceedings of the 40th International Conference on Machine Learning (ICML), Jul 2023We propose a meta-ability decoupling (MAD) paradigm, which brings together various object navigation methods in an architecture system, allowing them to mutually enhance each other and evolve together. Based on the MAD paradigm, we design a multiple thinking (MT) model that leverages distinct thinking to abstract various meta-abilities. Our method decouples meta-abilities from three aspects: input, encoding, and reward while employing the multiple thinking collaboration (MTC) module to promote mutual cooperation between thinking. MAD introduces a novel qualitative and quantitative interpretability system for object navigation. Through extensive experiments on AI2-Thor and RoboTHOR, we demonstrate that our method outperforms state-of-the-art (SOTA) methods on both typical and zero-shot object navigation tasks.
@inproceedings{dang2023multiple, title = {Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation}, author = {Dang, Ronghao and Chen, Lu and Wang, Liuyi and He, Zongtao and Liu, Chengju and Chen, Qijun}, booktitle = {Proceedings of the 40th International Conference on Machine Learning (ICML)}, pages = {6855--6872}, volume = {202}, year = {2023}, month = jul, }IEEE:
R. Dang, L. Chen, L. Wang, Z. He, C. Liu, and Q. Chen, “Multiple thinking achieving meta-ability decoupling for object navigation,” in Proceedings of the 40th international conference on machine learning (ICML), Jul. 2023
APA:
Dang, R., Chen, L., Wang, L., He, Z., Liu, C., & Chen, Q. (2023). Multiple Thinking Achieving Meta-Ability Decoupling for Object Navigation. Proceedings of the 40th International Conference on Machine Learning (ICML), 202, 6855–6872.
- DAT
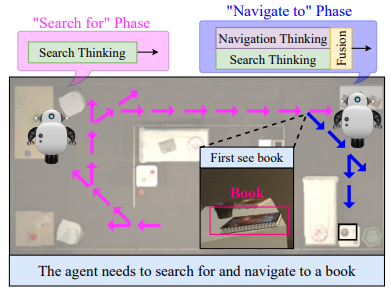 Search for or Navigate to? Dual Adaptive Thinking for Object NavigationRonghao Dang, Liuyi Wang, Zongtao He, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2023
Search for or Navigate to? Dual Adaptive Thinking for Object NavigationRonghao Dang, Liuyi Wang, Zongtao He, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2023"Search for" or "Navigate to"? When we find a specific object in an unknown environment, the two choices always arise in our subconscious mind. Before we see the target, we search for the target based on prior experience. Once we have seen the target, we can navigate to it by remembering the target location. However, recent object navigation methods consider using object association mostly to enhance the "search for" phase while neglecting the importance of the "navigate to" phase. Therefore, this paper proposes a dual adaptive thinking (DAT) method that flexibly adjusts thinking strategies in different navigation stages. Dual thinking includes both search thinking according to the object association ability and navigation thinking according to the target location ability. To make navigation thinking more effective, we design a target-oriented memory graph (TOMG) (which stores historical target information) and a target-aware multi-scale aggregator (TAMSA) (which encodes the relative position of the target). We assess our methods based on the AI2-Thor and RoboTHOR datasets. Compared with state-of-the-art (SOTA) methods, our approach significantly raises the overall success rate (SR) and success weighted by path length (SPL) while enhancing the agent’s performance in the "navigate to" phase.
@inproceedings{dang2023search, title = {Search for or Navigate to? Dual Adaptive Thinking for Object Navigation}, author = {Dang, Ronghao and Wang, Liuyi and He, Zongtao and Su, Shuai and Liu, Chengju and Chen, Qijun}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2023}, doi = {10.1109/iccv51070.2023.00758}, }IEEE:
R. Dang, L. Wang, Z. He, S. Su, C. Liu, and Q. Chen, “Search for or navigate to? Dual adaptive thinking for object navigation,” in International conference on computer vision (ICCV), 2023. doi: 10.1109/iccv51070.2023.00758
APA:
Dang, R., Wang, L., He, Z., Su, S., Liu, C., & Chen, Q. (2023). Search for or Navigate to? Dual Adaptive Thinking for Object Navigation. International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv51070.2023.00758
2022
- DOA
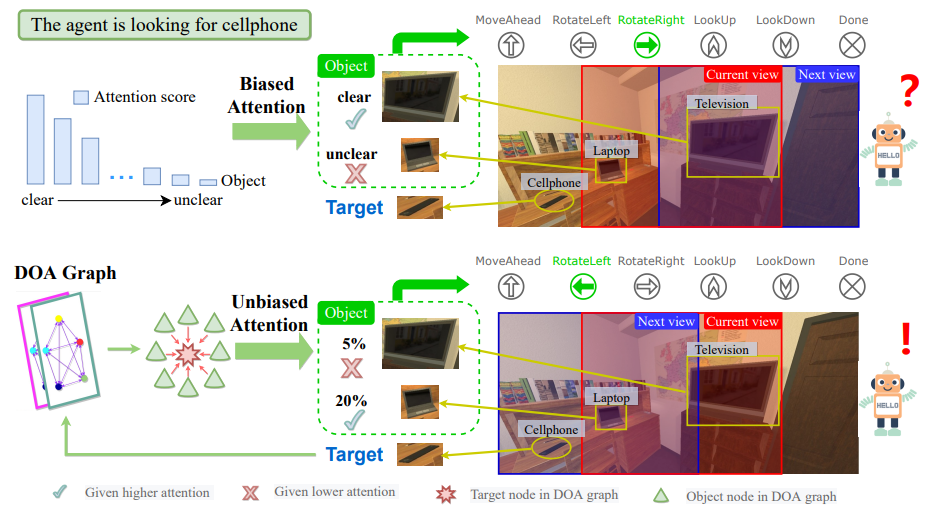 Unbiased Directed Object Attention Graph for Object NavigationRonghao Dang, Zhuofan Shi, Liuyi Wang, and 3 more authorsIn Proceedings of the 30th ACM International Conference on Multimedia, 2022
Unbiased Directed Object Attention Graph for Object NavigationRonghao Dang, Zhuofan Shi, Liuyi Wang, and 3 more authorsIn Proceedings of the 30th ACM International Conference on Multimedia, 2022Object navigation tasks require agents to locate specific objects in unknown environments based on visual information. Previously, graph convolutions were used to implicitly explore the relationships between objects. However, due to differences in visibility among objects, it is easy to generate biases in object attention. Thus, in this paper, we propose a directed object attention (DOA) graph to guide the agent in explicitly learning the attention relationships between objects, thereby reducing the object attention bias. In particular, we use the DOA graph to perform unbiased adaptive object attention (UAOA) on the object features and unbiased adaptive image attention (UAIA) on the raw images, respectively. To distinguish features in different branches, a concise adaptive branch energy distribution (ABED) method is proposed. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 7.4%, 8.1% and 17.6% increase in success rate (SR), success weighted by path length (SPL) and success weighted by action efficiency (SAE), respectively
@inproceedings{dang2022unbiased, title = {Unbiased Directed Object Attention Graph for Object Navigation}, author = {Dang, Ronghao and Shi, Zhuofan and Wang, Liuyi and He, Zongtao and Liu, Chengju and Chen, Qijun}, booktitle = {Proceedings of the 30th ACM International Conference on Multimedia}, pages = {3617--3627}, year = {2022}, doi = {10.1145/3503161.3547852}, }IEEE:
R. Dang, Z. Shi, L. Wang, Z. He, C. Liu, and Q. Chen, “Unbiased directed object attention graph for object navigation,” in Proceedings of the 30th ACM international conference on multimedia, 2022, pp. 3617–3627. doi: 10.1145/3503161.3547852
APA:
Dang, R., Shi, Z., Wang, L., He, Z., Liu, C., & Chen, Q. (2022). Unbiased Directed Object Attention Graph for Object Navigation. Proceedings of the 30th ACM International Conference on Multimedia, 3617–3627. https://doi.org/10.1145/3503161.3547852